





With GraphQL quickly taking over the internet, it’s no surprise that a number of companies like GitHub, PayPal, and Airbnb have adopted this technology. GraphQL is a data query and manipulation language and was released by Facebook in 2015 to provide a modern approach to developing web APIs.
By design, GraphQL’s functionality is separated into two parts:
-
Structure
-
Behavior
One of the key features that determines the server’s behavior is called resolver functions. Resolver functions are functions that resolve a value for a type or field in a schema.
In this article, you'll learn what resolvers are, how they work within a GraphQL schema, and why they're essential for efficiently fetching data. By the end, you'll have a clearer understanding of how to use resolvers in your GraphQL applications.
Anatomy of a GraphQL Resolver
A GraphQL schema describes the shape of your data graph by defining types with fields, and it specifies what queries and mutations are available. Every field in a GraphQL schema is essentially backed by a resolver, and that resolver is then responsible for grabbing the data for its respective field. These resolvers are often organized into a resolver map, which is a structured object that maps each schema field to its corresponding resolver function.
Using resolvers improves data processing and efficiency because instead of getting invoked on every request, it is only invoked when a user requests the data.
Below, we have declared a User type and a schema with a root Query type. Let’s look at the example below of a resolver function for the user field on the Query type:
const UserType = new GraphQLObjectType({
name: 'User',
fields: {
id: { type: GraphQLID },
name: { type: GraphQLString },
},
})
const schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: {
user: {
type: UserType,
args: {
id: { type: GraphQLID },
},
resolve: (root, args, context, info) => {
const { id } = args // the `id` argument for this field is declared above
return fetchUserById(id) // hit the database
},
},
},
}),
})
The resolver type signature contains four parameters: root, args, context, and info, and can return an object or promise.
Let’s look a little deeper at the arguments that get passed into the resolver and what they can contain.
While learning GraphQL fundamentals, you will most likely be working more with the root and args parameters. We will go through a simple example of querying for a user id and name by passing in two arguments into said parameters.
Execution Flow
In the example below, the query is requesting three fields: user, id, and name. Each field will invoke a resolver function, which totals to three resolvers. Let's examine them in action:
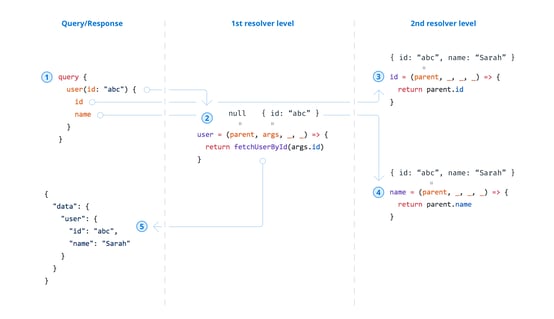
If a field relies on the result of another resolver, it is passed down as the parent argument, often referred to as the parent resolver. This ensures that each resolver can access the data resolved by the previous one, enabling smooth data flow between fields.
Steps of Execution Flow
In the example provided, we are returning an object with the requested data. Not all data will arrive in this format though - just something to keep in mind.
After your GraphQL server retrieves the data, you’re welcome to send it to your front-end for display. In our simple example, we worked with user names and IDs. Because GraphQL serves as an alternative to REST, it can also query numerous kinds of data such as home rental listings, authors and books at a library, restaurant information, and user reviews, but with a single endpoint. There is a sea of endless possibilities and the GraphQL world is your oyster.
GraphQL Resolvers: Next Steps
This article unveils one of the many flexible and rich components that the GraphQL query language offers and how it’s changing the web service architecture standards. Even though resolvers are just functions, they play an important role by implementing the API. Understanding this piece strengthens the foundation for adopting GraphQL into your application.
When scaling your GraphQL API, keeping an eye on resolver performance becomes key. Complex queries involving nested resolvers can significantly slow down your application. Reducing database calls, caching results, and monitoring execution time will get you data faster and improve your API performance.
References:
More on GraphQL Resolvers
What is the difference between schema and resolver in GraphQL?
In GraphQL, a schema defines the structure of your data and the relationships between different types. It outlines the types of data that can be queried or mutated, the fields within those types, and the operations (queries and mutations) that clients can perform.
On the other hand, a resolver is a function responsible for fetching the data for a specific field in the schema. When a query is executed, the corresponding resolver is called to retrieve the actual data from a data source (like a database or an API) based on the client's request. While the schema defines what data can be requested and its shape, resolvers implement the logic needed to fetch that data, providing the connection between the schema and the underlying data sources.
What is a default resolver in GraphQL?
A default resolver is a function provided by the GraphQL server to fetch data for a field if no custom resolver is defined. When a GraphQL query asks for a field, the default resolver will look for a property in the source object and return the value. This allows for quick and easy data retrieval without having to write a separate resolver for each field.
Default resolvers are especially useful for simple data models as they reduce the amount of boilerplate code. But if the field needs more complex logic – like fetching from a database or applying some transformation – a custom resolver should be defined to handle that.
What is a user resolver in GraphQL?
The user resolver is a type of resolver you define to get data for a specific field in your schema, like fetching a user from a database. Unlike the default resolver, which fetches the value from the source object, the user resolver allows you to implement custom logic to handle more complex data retrieval or transformation.
How do you log resolver timings in GraphQL?
To log resolver timings in GraphQL, you can wrap your resolver functions with timing logic to measure how long each resolver takes to execute. One common way is to use console.time and console.timeEnd, or a more robust monitoring solution like Apollo Server plugins for advanced metrics. Here’s a simple approach using console.time and console.timeEnd:
Here's a basic example:
const resolvers = {
Query: {
user: async (parent, args, context, info) => {
console.time('User Resolver');
const user = await fetchUserById(args.id);
console.timeEnd('User Resolver');
return user;
},
posts: async (parent, args, context, info) => {
console.time('Posts Resolver');
const posts = await fetchPosts();
console.timeEnd('Posts Resolver');
return posts;
},
},
};
Make sure to log which resolver it was (the field name), how long the resolver took, the parent object, and whether any inputs slow things down.