Diagramming System Design: URL Shorteners
Shorthand links are everywhere. URL shorteners have gained in popularity over the years, from...




Amazon’s Simple Storage Service (S3), launched in 2006, is a highly scalable and durable cloud object storage service. It is a massively scalable storage service that utilizes object storage technology, emphasizing its durability, availability, and performance. It has become a standard in the industry, widely adopted not just by Amazon Web Services (AWS), but also by providers like Cloudflare, Backblaze, and Google Cloud Storage. Known for its simplicity, cost-effectiveness, and virtually unlimited capacity, S3 is an essential system for storing large volumes of unstructured data.
In this article, we’ll explore how S3 achieves scalability, its core mechanisms, and the tradeoffs involved in designing such a system.
Amazon S3 provides a reliable and scalable way to store and retrieve data from anywhere on the internet. It’s designed for use cases like data lakes, backups, and disaster recovery, and can handle objects up to 5 TB in size. Managing and securing data stored on Amazon S3 is crucial, with features like encryption, access control, and various storage classes tailored to different data retention needs. Whether you’re storing multimedia files or managing big data, S3 scales effortlessly to meet growing data needs without compromising performance or reliability.
Amazon S3 offers a variety of storage classes, each designed to meet different data storage needs. These storage classes provide varying levels of durability, availability, and performance, allowing users to choose the most cost-effective option for their specific use case. Whether you need to store frequently accessed data, infrequently accessed data, or long-term archive data, Amazon S3 has a storage class that fits your requirements.
Amazon S3 provides several storage class options, each tailored to different access patterns and cost considerations:
S3 Standard: This is the default storage class, optimized for frequently accessed data. It offers high durability and availability, making it suitable for critical data that needs to be accessed often. The cost is $0.023 per GB-month.
S3 Standard-IA (Infrequent Access): Designed for data that is accessed less frequently but still requires rapid access when needed. It offers a lower cost per GB-month compared to S3 Standard, priced at $0.0125 per GB-month.
S3 One Zone-IA: This class is also for infrequently accessed data but stores data in a single availability zone, offering a lower cost at $0.01 per GB-month. It is ideal for data that can be easily recreated if lost.
S3 Glacier Instant Retrieval: Tailored for archive data that needs to be accessed quickly. It provides a low cost of $0.004 per GB-month, making it suitable for data that is rarely accessed but requires immediate retrieval.
S3 Glacier Flexible Retrieval: This class is designed for archive data with flexible retrieval times, offering a lower cost of $0.0036 per GB-month. It is ideal for data that can tolerate longer retrieval times.
S3 Glacier Deep Archive: The most cost-effective option for long-term archive data, priced at $0.00099 per GB-month. It is perfect for data that is rarely accessed and can tolerate longer retrieval times.
Each storage class in Amazon S3 is designed to provide a balance between cost and performance, allowing users to optimize their storage costs while ensuring data availability and durability. By selecting the appropriate storage class, users can effectively manage their storage costs and meet their specific data access requirements.
Amazon S3 is designed around the concept of object storage, where data is stored as objects within buckets. Each object consists of the data itself, metadata, and a unique identifier. When users upload or retrieve data, S3 handles these objects across its distributed architecture.
S3’s underlying infrastructure ensures high durability by replicating objects across multiple availability zones within a region. This replication strategy guarantees that even if one zone experiences a failure, the data remains accessible from another zone, offering 99.999999999% (11 nines) durability.
S3 is also highly scalable, meaning you can store an unlimited number of objects without managing the underlying infrastructure. Requests to S3 are handled through REST APIs, and its partitioned architecture ensures that as storage needs grow, performance remains consistent.
Moreover, S3 is integrated with other AWS services like Lambda for event-driven processing, CloudFront for content delivery, and S3 Glacier for cost-effective archival storage. This flexibility makes it a powerful tool for handling a wide variety of workloads, from data lakes and big data analytics to backups and disaster recovery.
Let's start by exploring the concept of object storage in more details. Storage systems can generally be classified as:
Block storage: Blocks are the smallest group of data that we can manage. Blocks are typically 512 bytes to 4 KiB in size, accessible by their memory address (mind the difference between KB and KiB). Operating systems use block storage to manage data in file systems; databases manage blocks directly to optimize performance.
File storage: Built on top of block storage, file storage is a more familiar abstraction to most users. File storage enables us to manage data in files and directories laid out in a hierarchical structure, which abstracts away the complexity of direct block management.
Object storage: By contrast, object storage trades performance for scale at lower cost. Where block and file storage quickly read and write data by relying on a specific format, object storage more slowly reads and writes data and metadata items (together, “objects”) in a plain, flat structure.
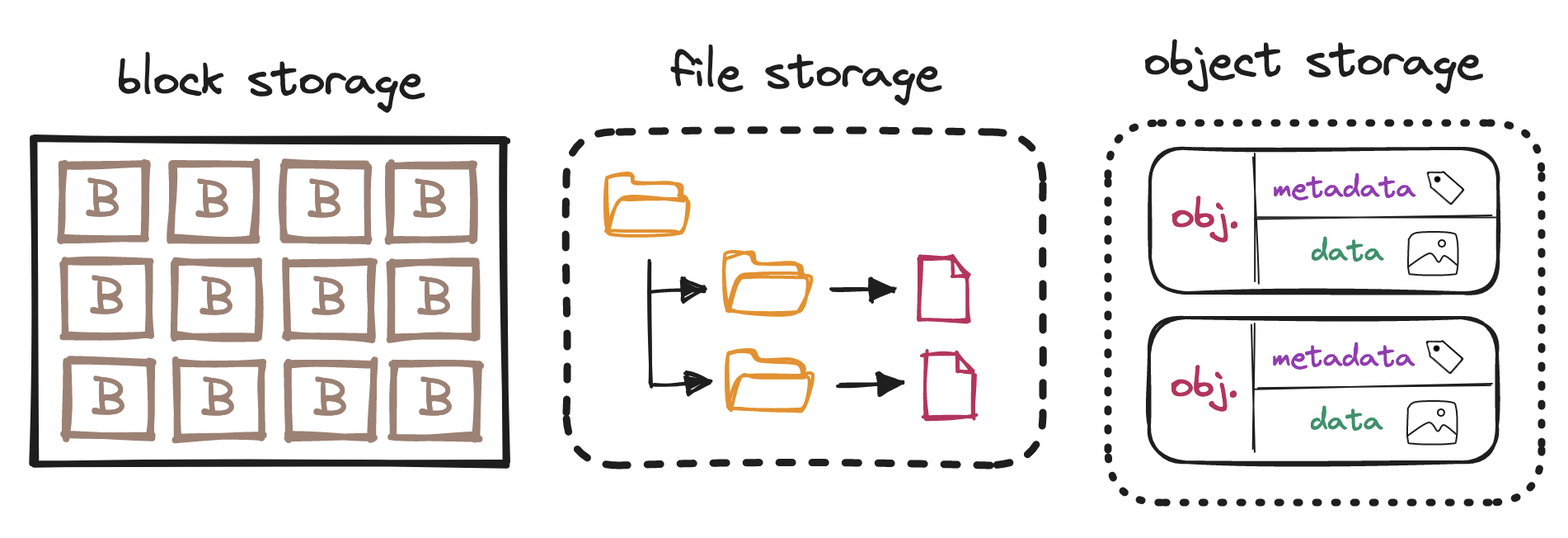
An object is an immutable piece of…
data, a sequence of bytes, e.g. the blob of bytes of binary data that makes up an image, and
its separate but associated metadata, key-value pairs describing the actual data, e.g. the name of the image.
Mind the immutability: we can delete or overwrite an object, but we cannot patch it. Objects are assigned URIs and most often accessed via a network request.
URI: https://s3.example.com/album/picture.png
In the example, picture.png is the object and album is a bucket. What is a bucket? Organizing vast amounts of data in a strictly flat structure can be a challenge, so S3 offers buckets as top-level containers to place objects into. Notice that buckets are not themselves data, but rather metadata common to a group of objects.
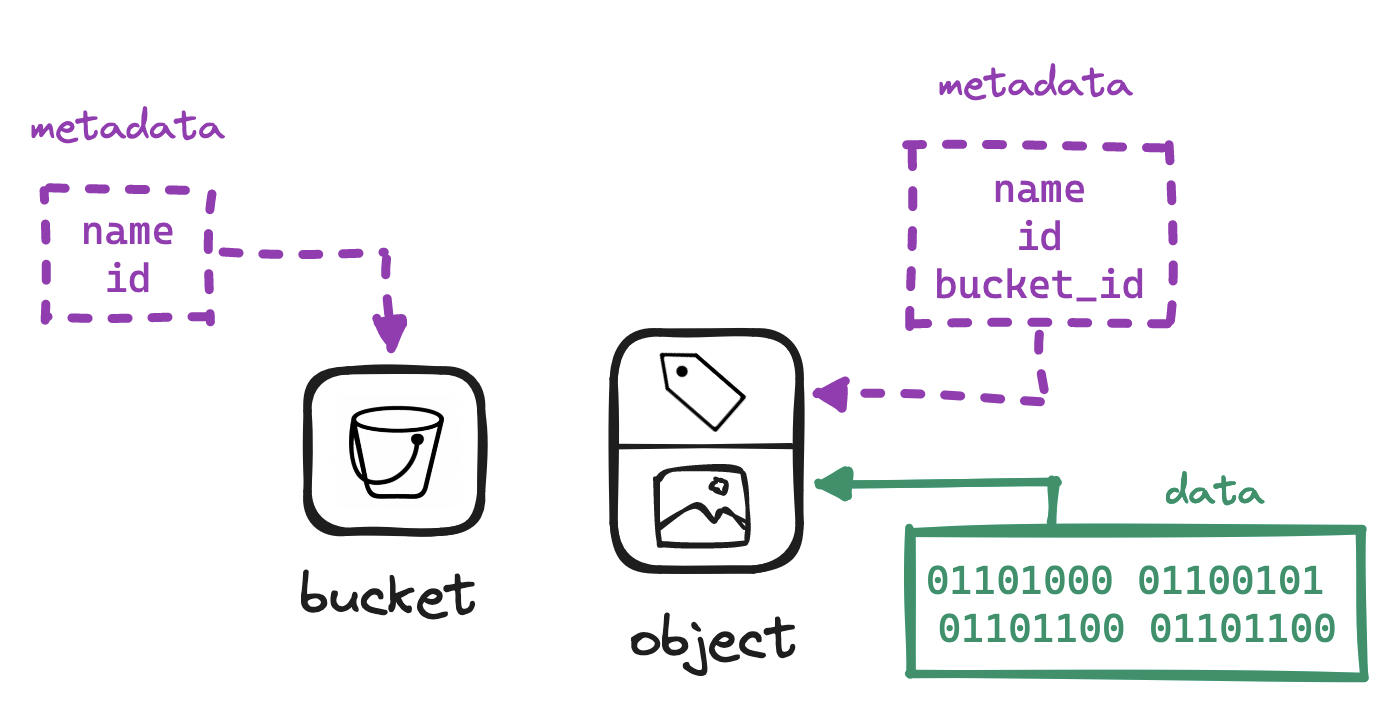
Buckets cannot be nested inside other buckets, but we can achieve nesting by having the object name resemble a filepath, with / delimiters. The section of the object name up to the last delimiter is known as a “prefix”, often used when querying. For example:
URI: https://s3.example.com/album/2023/september/picture.png
Bucket name: album
Object name: /2023/september/picture.png
Prefix: /2023/september/This layout where data and metadata are separate but associated is a callback to Unix filesystem design, where the inode (or index node) stores pointers to the blocks on disk that contain all the bits that make up the actual data.
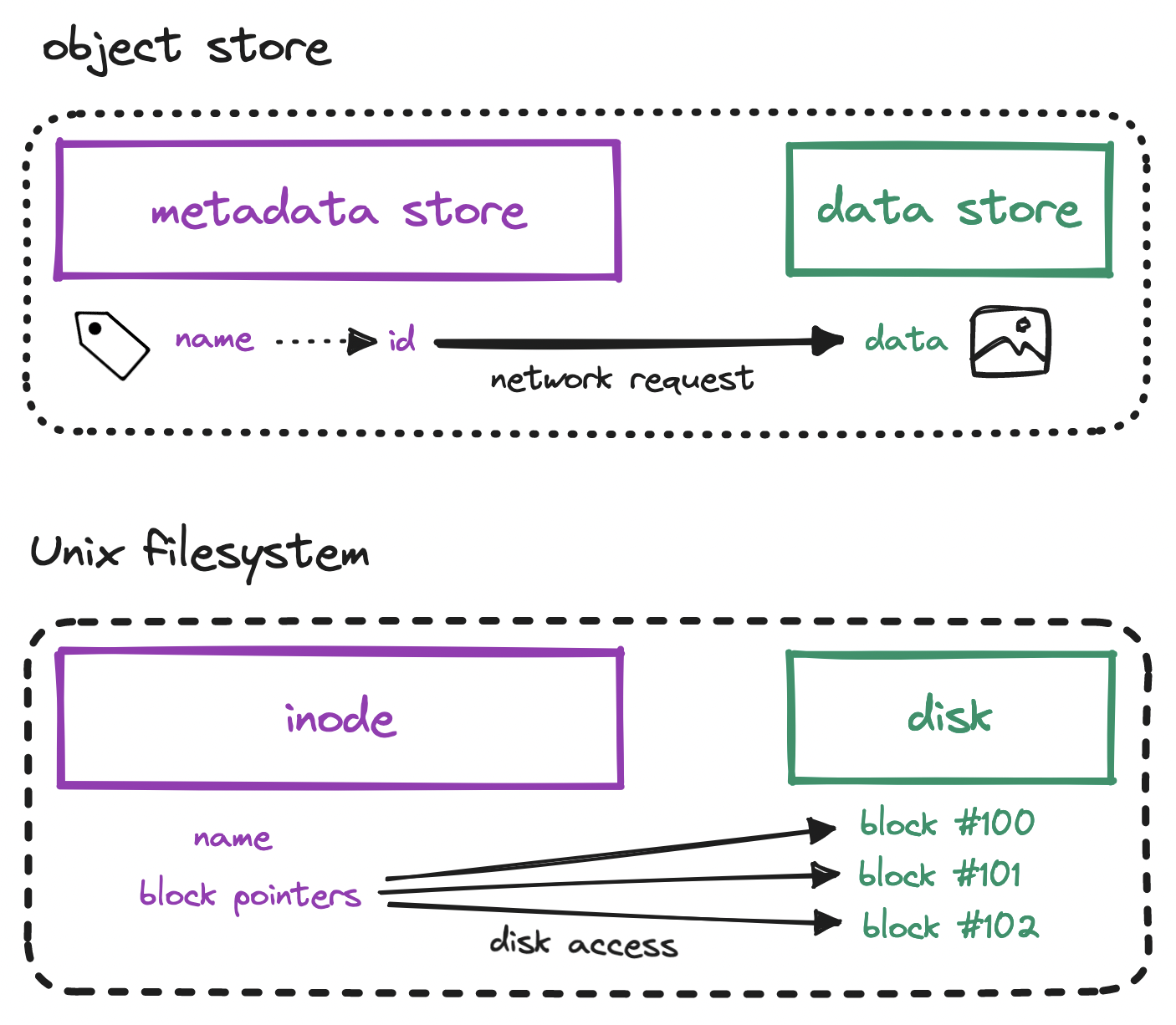
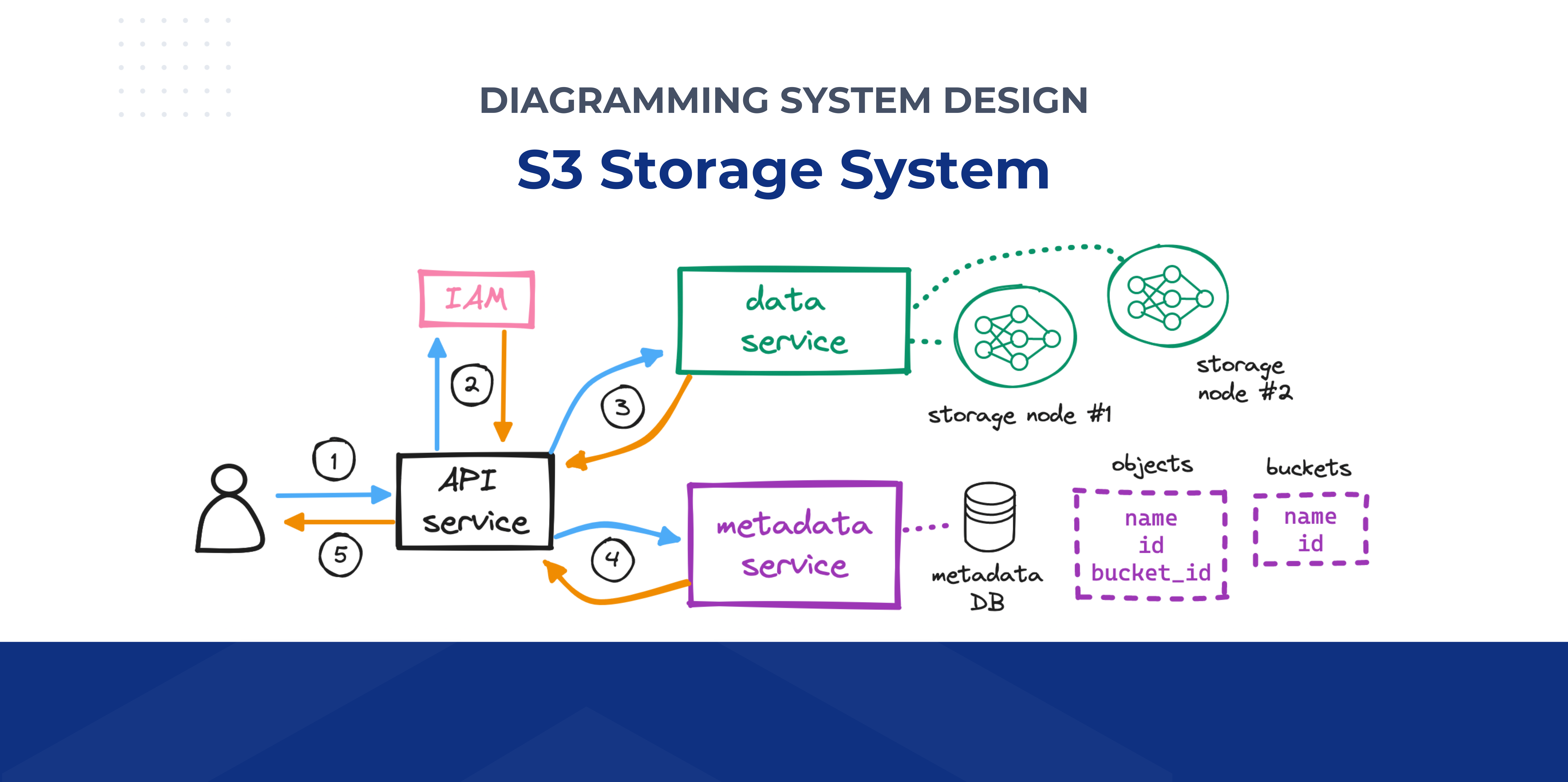
With this in mind, we can start to draft a high-level design for our S3 system:
For reading and writing objects to disk, we need to set up a data service.
For reading and writing metadata for those objects, a metadata service.
For enabling users to interact with our system, an API service.
For handling user auth, identity and access management (IAM).
That is, we need a central service that internally communicates with others that will…
verify who the requesting user is (“authentication”),
validate that their permissions allow the request (“authorization”),
create a container (“bucket”) to place content into,
persist (“upload”) a sequence of bytes and its metadata (“object”),
retrieve (“download”) an object given a unique identifier,
return a response with the result to the requesting user.
We can group these six operations into three flows: bucket creation, object upload, and object download. Full-blown S3 systems support many more flows, but these three make up the core of S3 and allow us to explore how most of the system works, from top to bottom.
Let’s begin by designing the object upload flow.
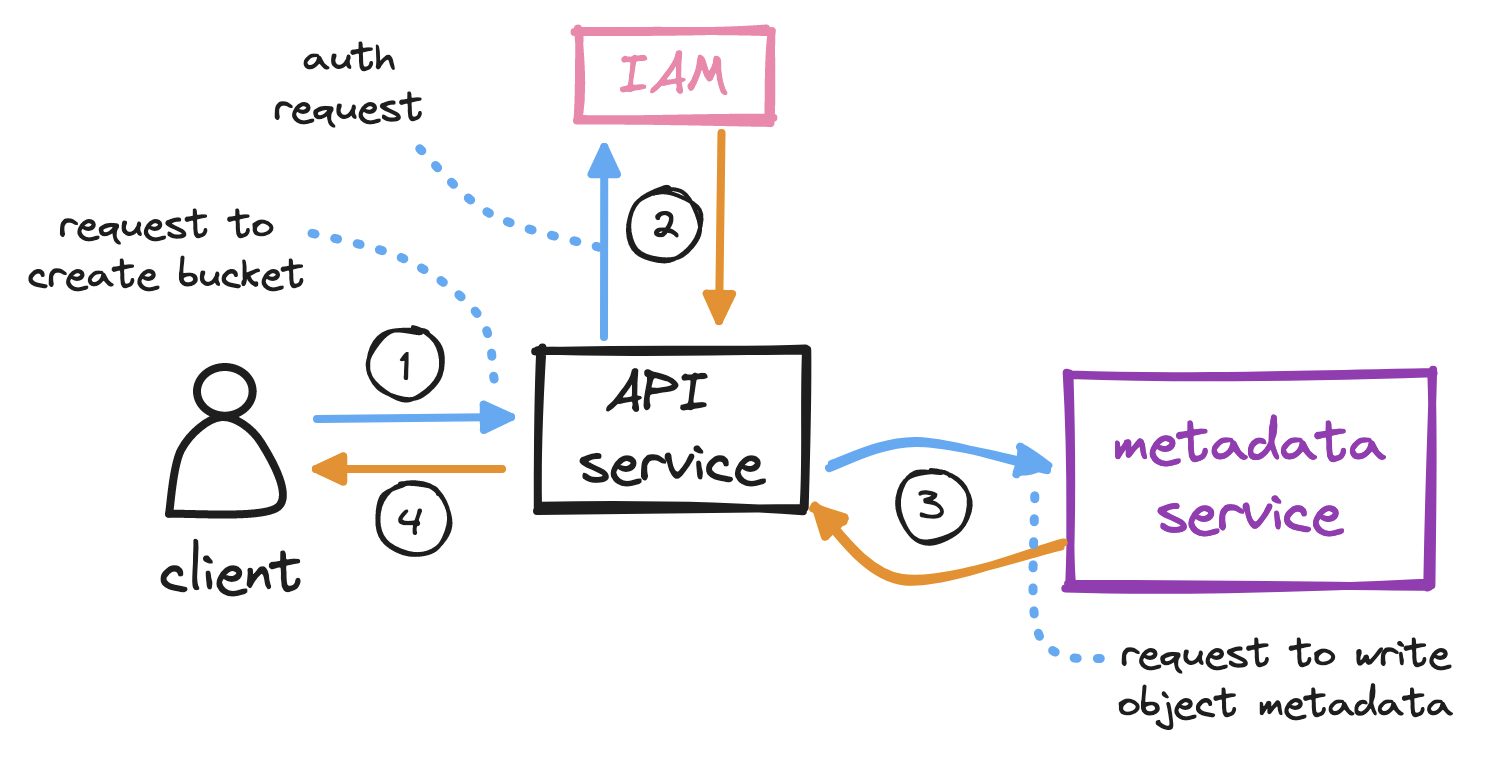
To create a bucket…
The client sends an HTTP PUT request to create a bucket.
The client’s request reaches the API service, which calls identity and access management (IAM) for authentication and authorization.
A bucket, as we mentioned, is merely metadata. On successful auth, the API service calls the metadata service to insert a row in a dedicated buckets table in the metadata database.
The API service returns a success message to the client.
To upload an object…
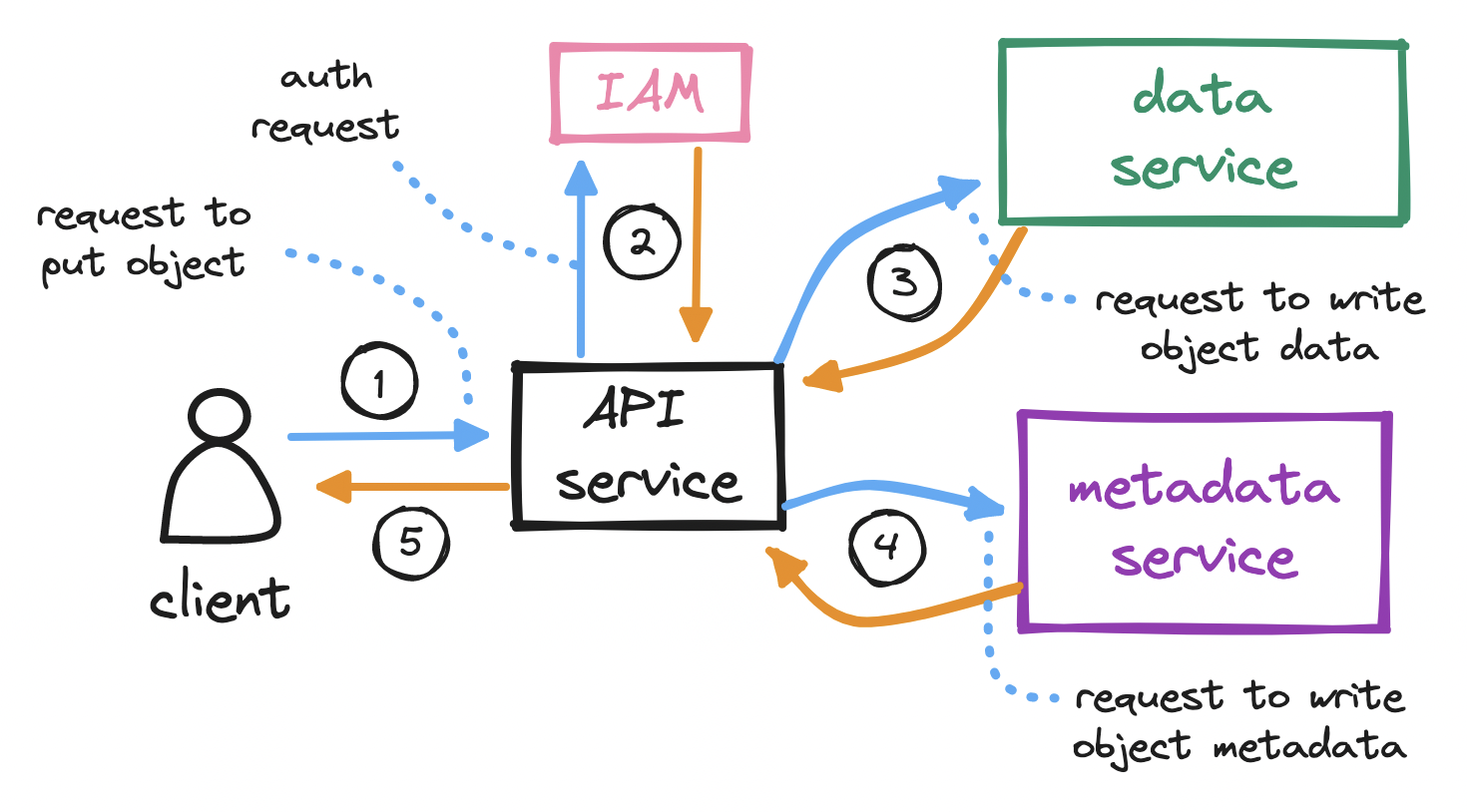
With the bucket created, the client sends an HTTP PUT request to store an object in the bucket.
Again, the API service calls IAM to perform authentication and authorization. We must check if the user has write permission on the bucket.
After auth, the API service forwards the client’s payload to the data service, which persists the payload as an object and returns its id to the API service.
The API service next calls the metadata service to insert a new row in a dedicated objects table in the metadata database. This row holds the object id, its name, and its bucket_id, among other details.
The API service returns a success message to the client.
To download an object…
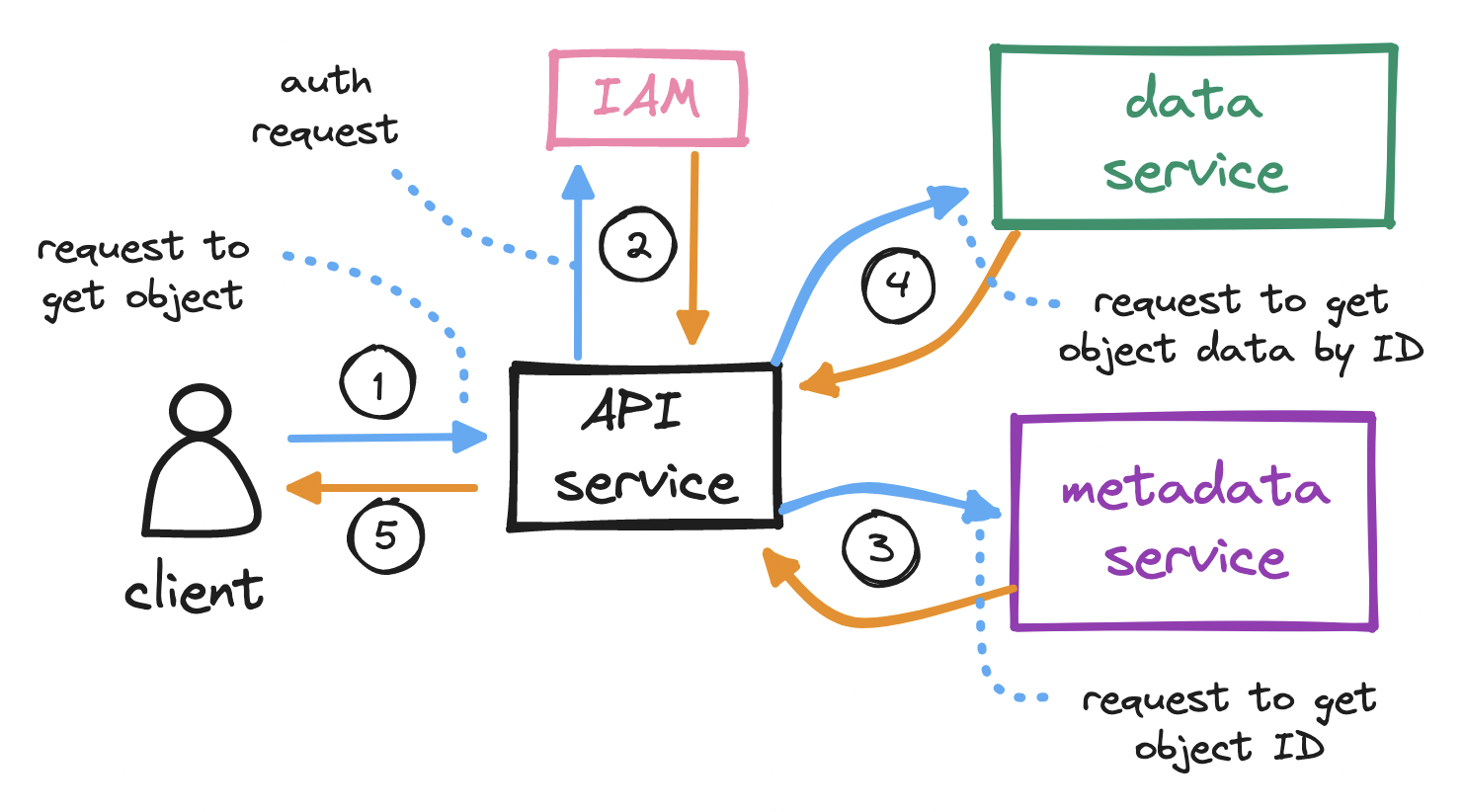
With the bucket created and the object uploaded, the client sends an HTTP GET request, specifying a name, to retrieve the object.
The API service calls IAM to perform authentication and authorization. We must check that the client has read access to the bucket.
Since the client typically sends in the object name (not its id), the API service must first map the object name to its id before it can retrieve the object. Hence, on successful auth, the API service calls the metadata service to query the objects table to locate the object id from its name. Note how, in the download flow, we visit the metadata service before the data service, as opposed to the upload flow.
Having found the object id, the API service sends it to the data service, which responds with the object’s data.
Finally, the API service returns the requested object to the client.
In our high-level design, two services are S3-specific and do most of the heavy lifting: the data service and the metadata service. Let’s dig into their details, starting with the most important one.
When considering replication, it's crucial to understand the costs and performance associated with data transfer to and from storage nodes. This includes evaluating transfer charges and the impact of different transfer methods on overall expenses.
The data service needs to be able to write and read a sequence of bytes to and from disk. In this context, a disk is often a hard disk drive (HDD) or solid-state drive (SSD); it can also be a network-attached storage (NAS) device, or even a virtual disk in a cloud environment.
For our purposes, a storage node is a group of any such disks, i.e., a bundle of space to write to and read from, and our data service will be responsible for managing these nodes. For fault tolerance, the data service will also need to replicate data across multiple storage nodes, each sending back a heartbeat to allow the data service to distinguish healthy nodes from failed nodes.
Amazon S3 allows users to store data as objects organized in buckets, offering various storage classes for different use cases such as mission-critical data or archival storage.
How do storage nodes fit into our design? Remember the interactions between the API service and the data service:
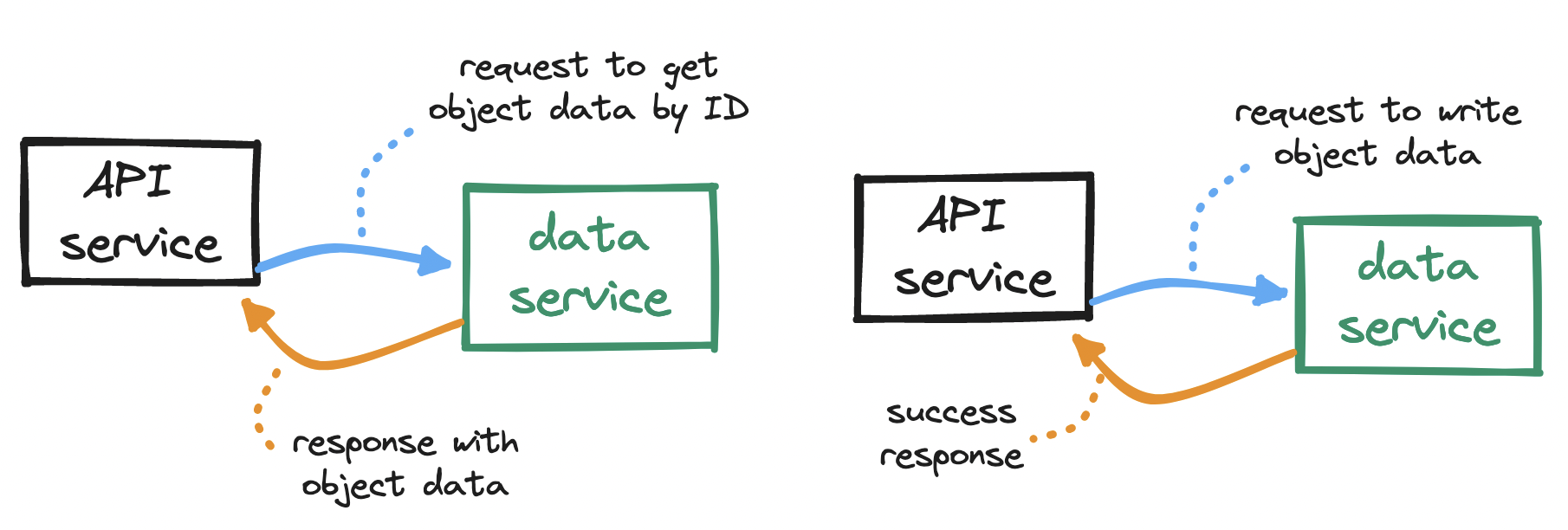
To serve requests from the API service, our data service will need to…
monitor the health of all storage nodes,
locate nodes to write to, distributing writes consistently,
locate storage nodes to read from, distributing reads consistently,
write objects to, and read objects from, storage nodes,
replicate objects across storage nodes.
These operations can be grouped. For example, we can group the first three into a selector subservice, and the last two into a reader-writer subservice.
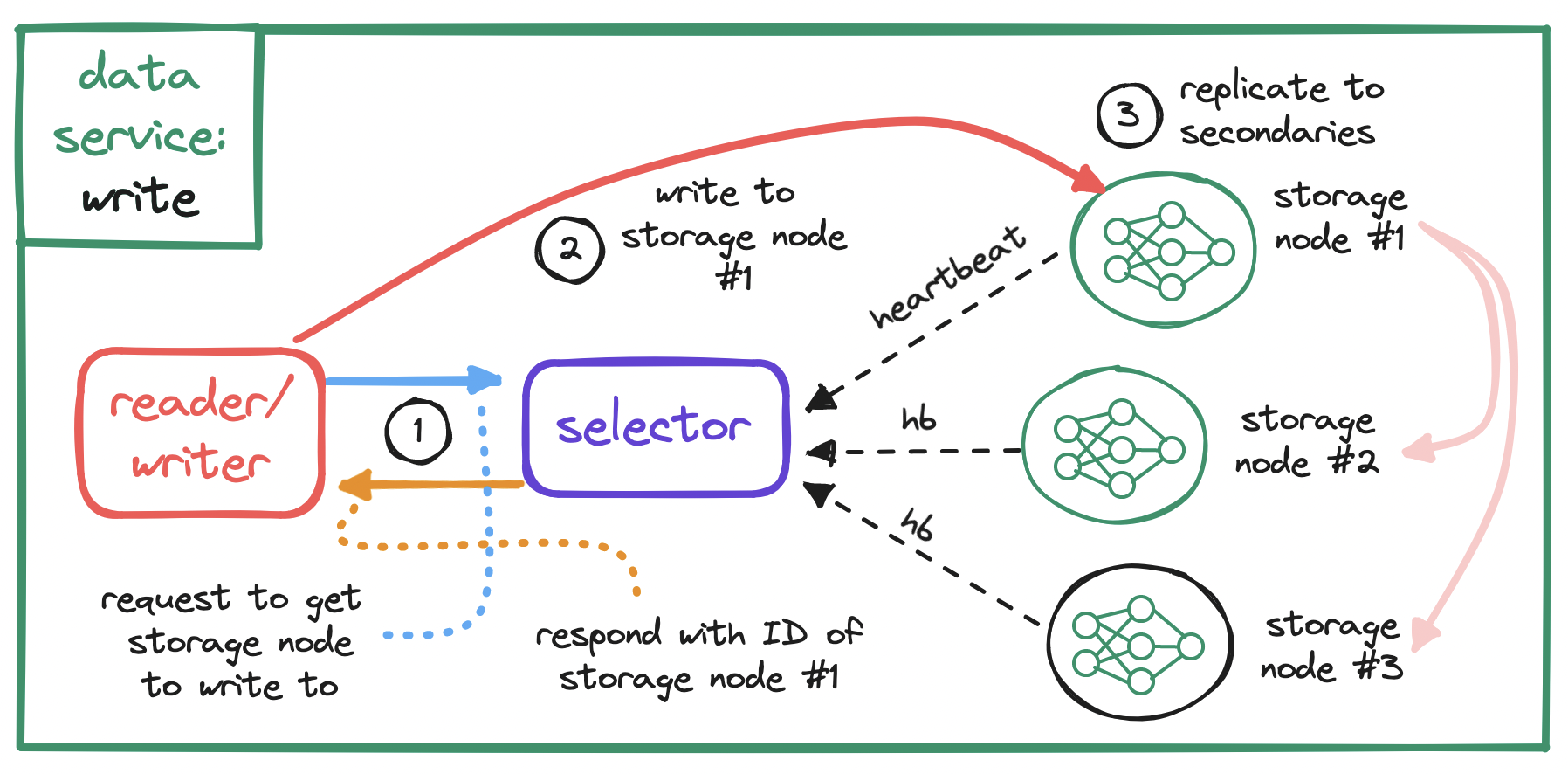
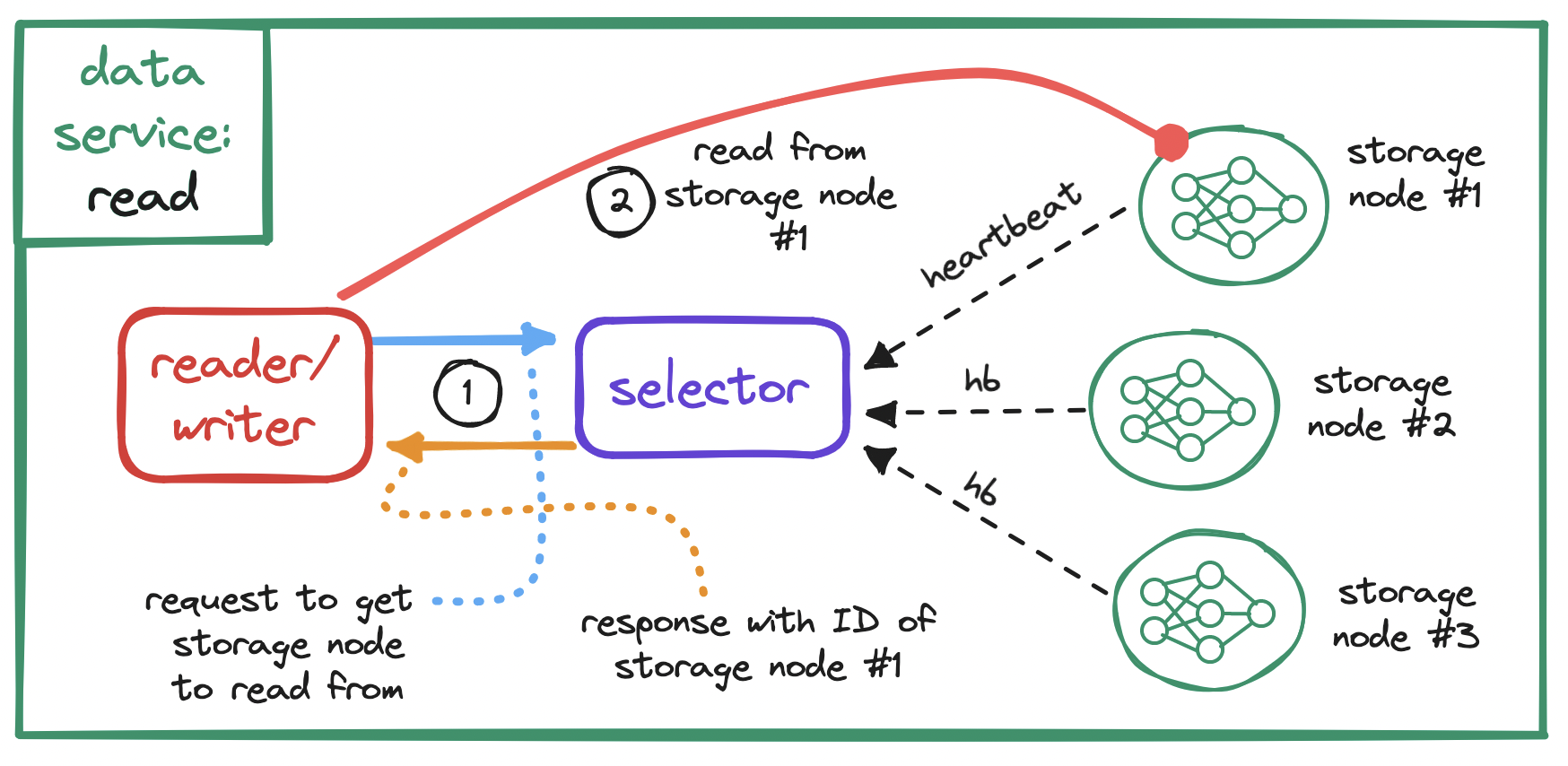
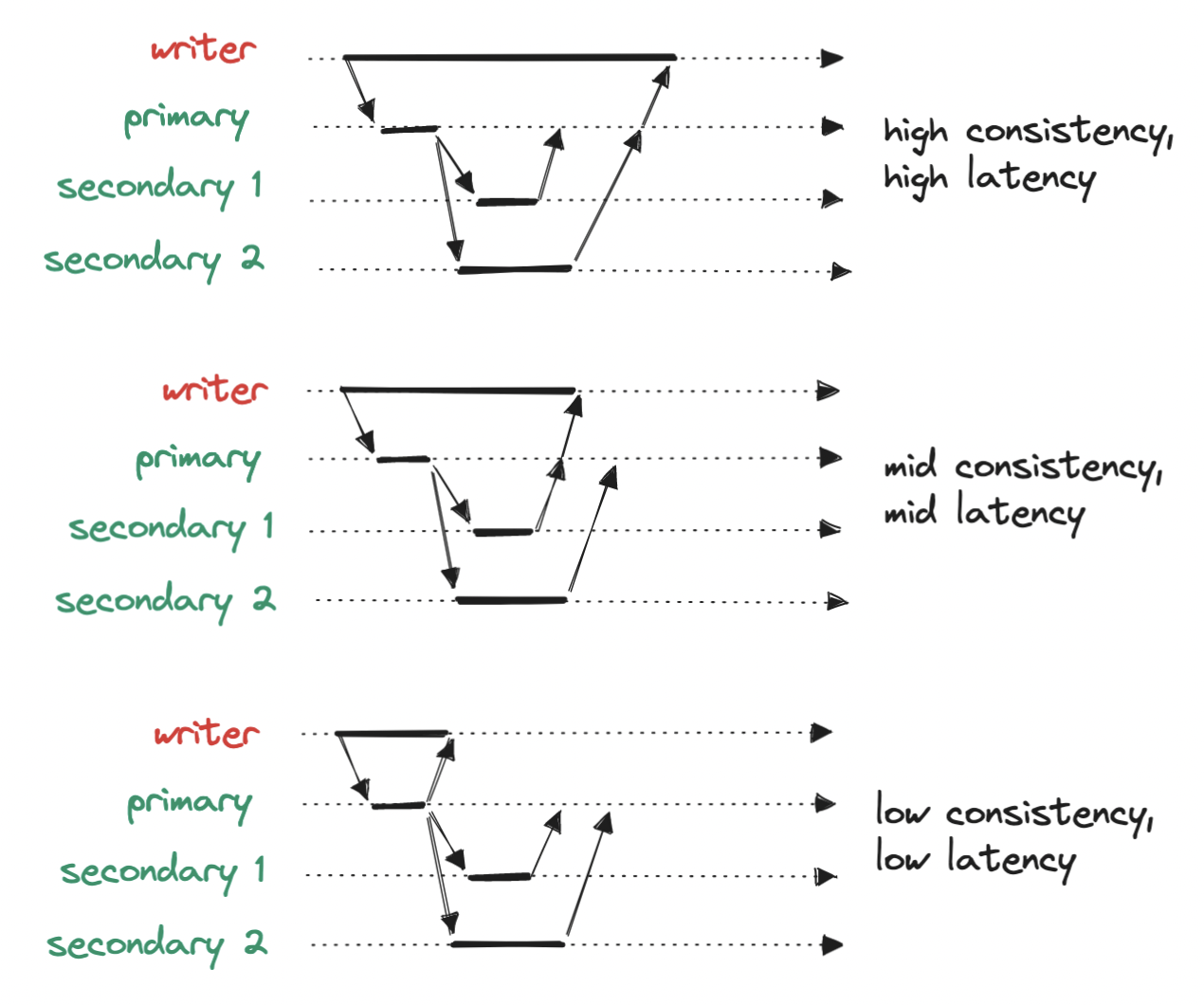
When it comes to replication, either for S3 or more generally, remember to keep in mind the tradeoff between consistency and latency. We may choose to write to a single node, respond immediately and replicate later, at the cost of data loss in case of replication failure; or we may choose to wait for partial or full replication before responding, at the cost of increased latency.
Let’s keep drilling down. How exactly do we write to a storage node?
The naivest solution would be to write each object as a single file in the storage node. However, each block is typically 4 KiB in size, so any objects smaller than this will waste disk space. What we need is a more compact way to store objects, ideally similar to how blocks work, but for objects.
To make the most out of our disk, we can write multiple small objects into a larger file, commonly known as a write-ahead log (WAL). That is, we append each object to a running read-write log. When this log reaches a threshold (e.g. 2 GiB), the file is marked as read-only (“closed”), and a new read-write log is created to receive subsequent writes. This compact storage process is what accounts for S3 objects being immutable.
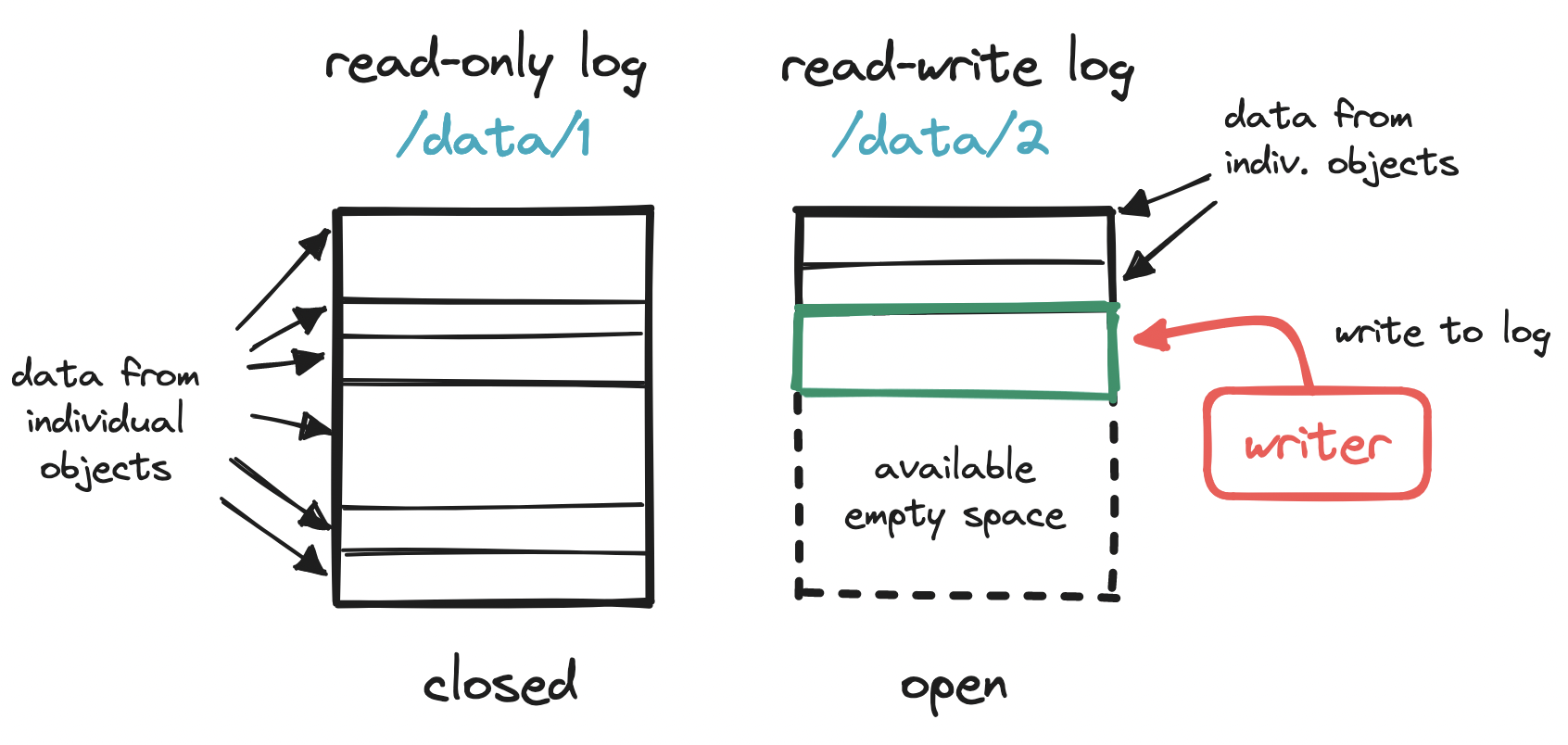
But how do we find an object across all these log files? Searching for an object with no indication of where it may have been written to (“sequential scan”) is not scalable.
To enable fast reading, we can embed a small database in the storage node (e.g. sqlite) to hold location details. Immediately after appending an object to the running read-write file, we turn to this embedded DB and store the object id, log filename, how far away the object is from the start of the file (its offset), and the object size. With these location details, we can later query the embedded DB and quickly find any object across all the log files in a storage node.
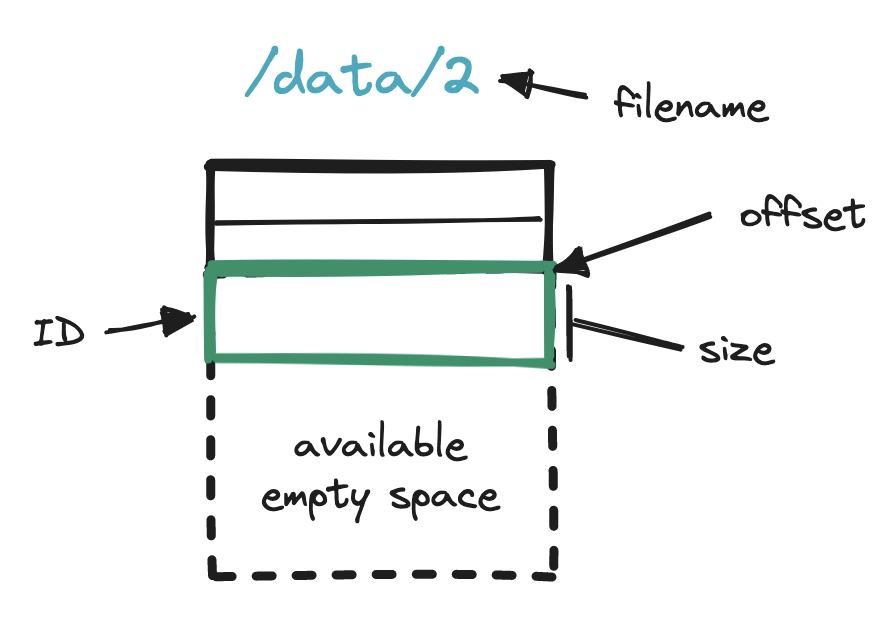
Our metadata service is simpler. This service will need to...
store metadata for buckets, for the bucket creation flow,
store metadata for objects, for the object upload flow,
find an object's metadata given its name, for the object download flow,
Hence our two tables may look like this:

Typically, S3 systems cap the number of buckets allowed per user, so the size of our buckets table will remain bounded. If each user has set up 20 buckets and each row takes up 1 KiB, then one million users will require ~20 GiB. This can easily fit in a single database instance, but we may still want to consider provisioning read replicas, for redundancy and to prevent a bandwidth bottleneck.
The objects table, on the other hand, will grow unbounded. The number of rows, conceivably in the order of billions, will exceed the capacity of any single database instance. How can we partition ("shard") this vast number of rows across multiple database instances?
If we shard by object.bucket_id, causing objects in the same bucket to end up in the same partition, we risk creating some partitions that will handle much more load than others.
If we shard by object.id, we can more evenly distribute the load. But remember: when we download an object, we call the metadata service and pass in both object.name and object.bucket_name in order to find object.id, which we then use to locate the actual data. As a result, this sharding choice would make a major query in the object download flow less efficient.
Hence we need a composite key. Given that an object's identifier is a combination of its name and bucket_name, we can hash both values into a single sharding key to even out the load, while also supporting the object download flow.
How would our design fare when expanding the system? Let’s consider a few more common features of S3 systems and how we could support them.
Data integrity is a key feature of S3. To prevent object loss, we have implemented heartbeats and replication across storage nodes, but this only defends against total node failure. What about data corruption in otherwise healthy nodes?
We need a guarantee that the data we read is the same as the data we wrote. One solution is to generate a fixed-length fingerprint (“checksum”) from each sequence of bytes we write, and to store that fingerprint alongside the sequence. Consider a fast hash function like MD5. Later, at the time of retrieval, immediately after receiving data, we generate a new checksum from the data we received, and compare the new checksum to the stored one. A mismatch here will indicate data corruption.
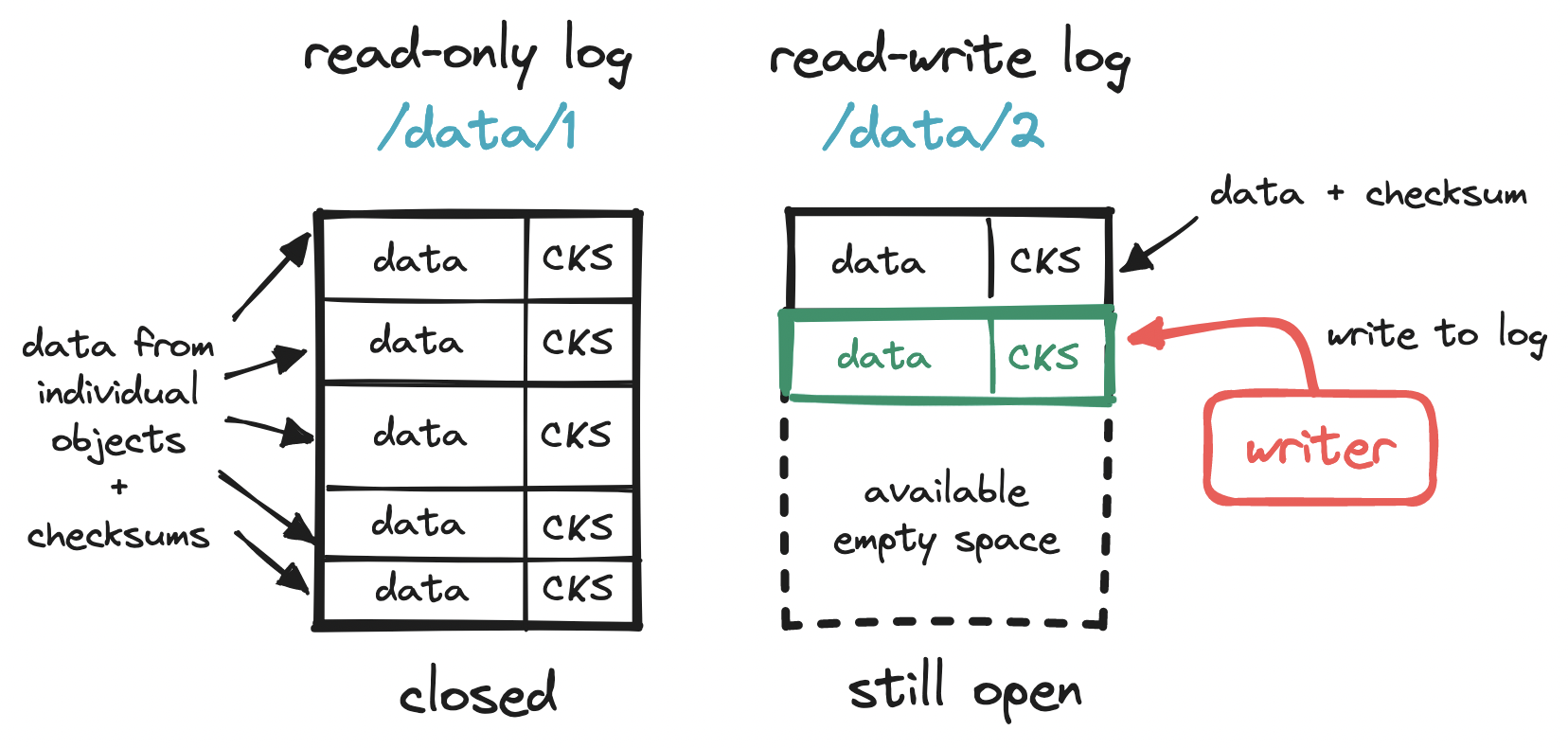
Another key feature of S3 is its vast storage space. To make the most out of our disk, we rely on a write-ahead log to store objects and a small embedded DB to locate them. With this setup, implementing object deletion is a matter of locating the object and marking it as deleted.
But a housekeeping issue remains. How do we handle garbage collection? Both deletion and data corruption will produce unused storage space, so we need a way to reclaim space that is no longer used. One solution is to periodically run a compaction process, which would…
find the valuable sections of a set of read-only log files,
write those valuable sections into a new log file,
update object location details in the embedded DB, and
delete the old log files.
S3 Intelligent-Tiering optimizes storage for rarely accessed data by automatically adjusting storage based on access patterns.
Similarly, versioning is a key feature of many S3 systems. With bucket versioning, we can store multiple versions of the same object in a bucket, and restore them - this prevents accidental deletes or overwrites. To some extent, versioning also lets us work around the immutability of the write-ahead log.
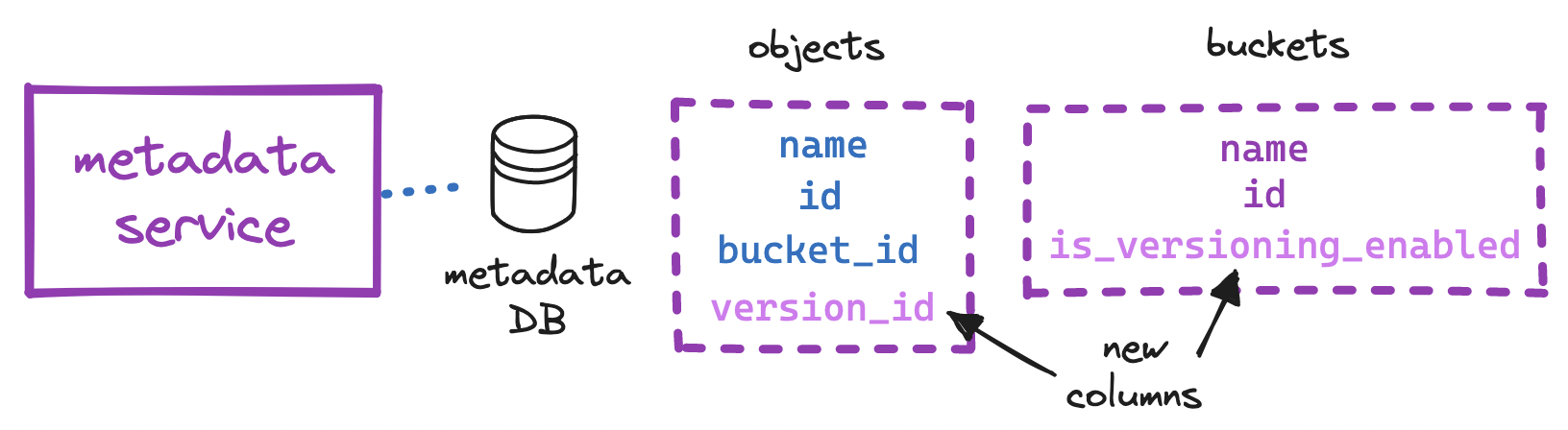
To implement versioning, we can begin by adding a boolean is_versioning_enabled column to the buckets table and an integer version_id column to the objects table. At the time of insertion, instead of overwriting the existing row, we can append a new row with the same object.bucket_id and object.name as the existing row, but with a new object.id and an incremented object.version_id. With versioning enabled, deleting an object will mark the version with the highest object.version_id as deleted, and retrieving an object will look up its latest non-deleted version.
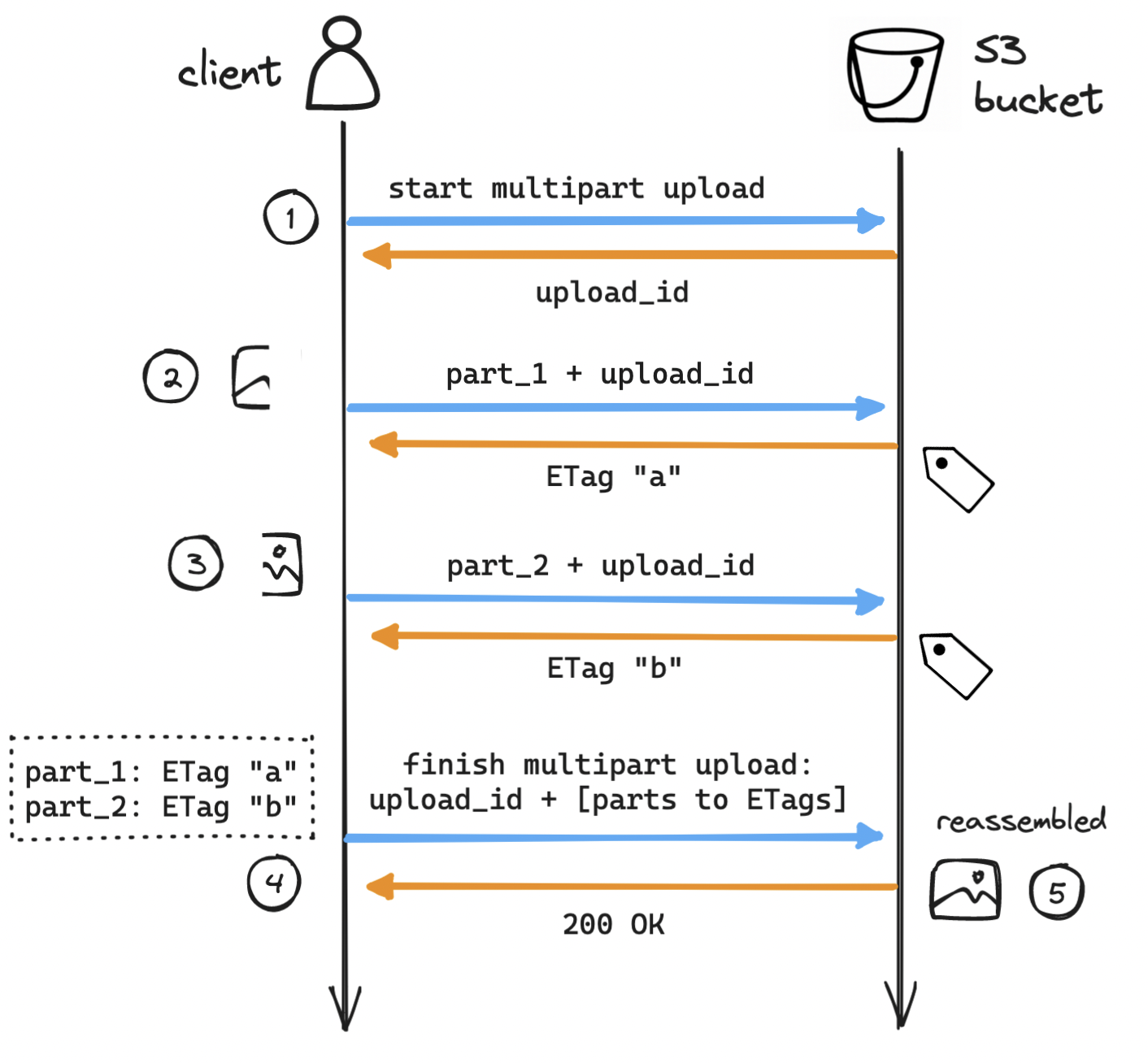
Multipart uploads are another common feature of S3 systems. With multipart uploads, we can upload objects in smaller parts, either sequentially or in parallel, and after all parts are uploaded, we reassemble the object from its parts. This is useful for large uploads (e.g. videos) that may take long and so are at risk of failing mid-upload. On upload failure, the client resumes from the last successfully uploaded part, instead of having to start over from the beginning. What could this look like?
The client requests S3 to initiate a multipart upload for a large object and receives an upload_id, a reference to the current upload session.
The client splits up the object into parts (in this example only two, often more) and uploads the first part labeled as part_1, including the upload_id. On success, S3 returns an identifier (ETag, or entity tag) for that successfully uploaded part of the object.
The client repeats the previous step for the second part, labeled as part_2, and receives a second ETag.
The client requests S3 to complete the multipart upload, including the upload_id and the mapping of part numbers to ETags.
S3 reassembles the large object from its parts and returns a success message to the client. The garbage collector reclaims space from the now unused parts.
S3 systems are complex beasts - this discussion only touches on the bare essentials of how they work. We have explored how object storage compares to other storage types, what the core flows of S3 look like, and how to design a system to support them. We have also considered expansions to our system, such as data corruption verification, garbage collection, object versioning, and multipart uploads, and how to support them without compromising the core design.
To delve deeper into the inner workings of S3, consider:
how to support automatic object expiration ("time to live"),
how to list out all objects in a bucket or with a given prefix,
how checksums can help verify the integrity of data uploads,
how to efficiently paginate object listings from sharded databases,
how erasure coding can contribute to data availability and redundancy.
S3 is the bedrock of cloud object storage. Learning about how it works, at both higher and lower levels, is a great way to become familiar with the core concepts behind highly available storage systems at scale.