
Diagramming System Design: Rate Limiters
All production-grade services rely on rate limiters - when a user may post at most five articles...




ChatGPT reached one million users in the first five days of product release. Needless to say, generative AI and associated tools are on top of everyone’s mind. Generative AI tools have various applications across multiple modalities, including text, imagery, music, code, and voices.
In this article, we’ll demystify generative AI for software engineers who are newer to artificial intelligence and machine learning:
Define generative AI
Introduce relevant machine-learning concepts
See the evolution of deep learning model types
Learn about the transformer architecture and key mechanisms
Learn about language transformers - Large Language Models (LLMs)
Identify limitations and challenges of generative AI models

According to IBM, “Generative AI refers to deep-learning models that can generate high-quality text, images, and other content based on the data they were trained on.” That’s a mouthful. Let’s unpack that definition piece by piece. Generative artificial intelligence (Gen AI) is a subset of AI capable of creating content such as text, images, and music.
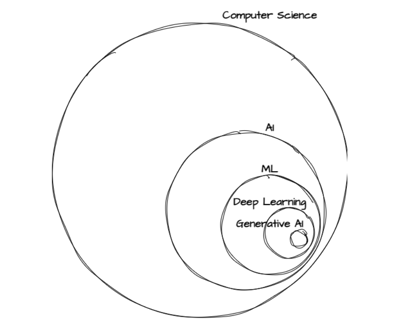
Hierarchy of the related topics. Source: Author
A generative AI system is a subset of AI that creates various forms of data through advanced models, leveraging technologies like deep neural networks to learn complex patterns from large datasets and perform diverse tasks across multiple industries.
Hierarchy of the related topics. Source: Author
Let’s start at the top of the hierarchy. Computer science (CS) is the field that studies how computers and computations can be used to solve problems efficiently.
Artificial intelligence (AI) is a discipline of CS that focuses on creating computer models that “imitate intelligent human behavior … [enabling computers] to perform complex tasks in a way that is similar to how humans solve problems.”
Machine learning (ML) is a branch of AI. It involves creating computer models “that give computers the ability to learn… [and] to program themselves through experience.”
Deep learning is a sub-branch of ML, built on top of neural networks (more on that later).
As the word generative suggests, generative AI models create new content based on the input prompt and training data. There are many types of input and output content, but the major categories are language, visual, auditory, and data. Some generative AI models are multimodal, with the capability to create content across multiple types of media – for example, from text to images or text to videos. One reason for generative AI’s popularity is its widespread applicability.
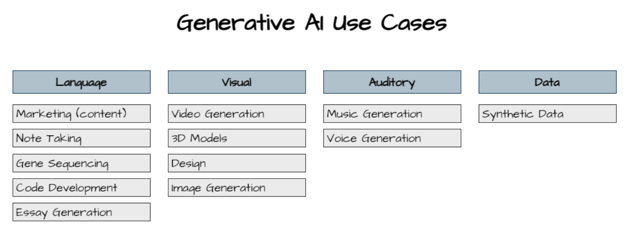
Generative AI use cases by the major categories of language, visual, auditory, and data. Source: Author, inspired by https://www.nvidia.com/en-us/glossary/data-science/generative-ai/
Generative AI use cases by the major categories of language, visual, auditory, and data. Source: Author, inspired by https://www.nvidia.com/en-us/glossary/data-science/generative-ai/
A model, in machine learning, refers to a set of algorithms trained on a specific dataset.
As of now, various generative AI models have been developed and funded by big companies and universities, such as OpenAI, Nvidia, Google, Meta, and UC Berkeley. Each institution decides whether to keep its model private or public. They also determine the methods of access and monetization.
OpenAI has developed generative AI models including GPT-4, Whisper, and DALL-E 2. While the models are private, the company offers API access to these models with a pricing structure. OpenAI also offers ChatGPT, a chat application built on its GPT models, as a freemium product. Additionally, Microsoft has partnered with OpenAI on Bing Image Creator, which is powered by DALL-E.
Neural networks are a subset of machine learning loosely modeled on circuits of neurons in the human brain. A neural network can be visually represented as a fully interconnected, directed graph structure organized by layers.
There are several key components in a neural network:
Neurons or Nodes - Each neuron or node is basically a function that takes in inputs and produces an output. An individual node may receive input from several connected nodes in the previous layer and may send output to several connected nodes in the next layer.
Weight - A node assigns a weight to each incoming connection to indicate how important that data source is. The node then computes the weighted sum of all inputs.
Threshold or Bias - Bias equates to the negative threshold and is added to the total weighted sum before it is passed through the activation function. The threshold value is a gatekeeper that determines whether the node passes its output to the next layer or not.
Activation Function - A function that takes in the total weighted sum and bias to produce the node’s output. Modern neural networks use a nonlinear function, such as the commonly used Sigmoid function, because complex, real-world problems are non-linear. The Sigmoid function produces a value between 0 and 1.
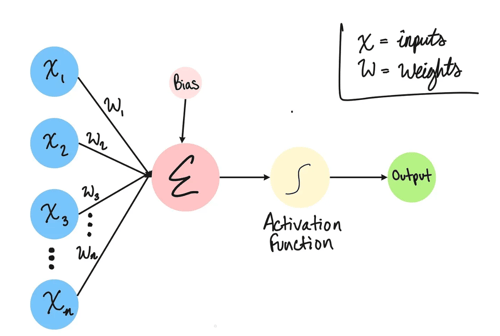
A diagram of a neuron and its components. Source: https://medium.com/@tiffanytha.sj/introduction-to-neural-networks-b56d8148bae2
Layers - There is 1 input layer, 1 output layer, and 1 or more hidden layers in between them. The deep in deep learning refers to the depth of layers in a neural network; a neural network comprised of more than three layers is considered a deep learning model.
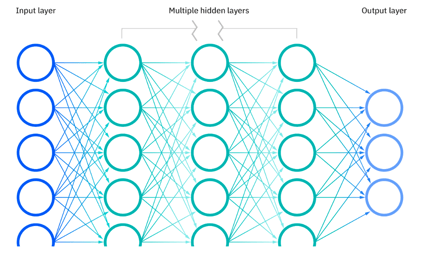
A visual representation of the layers in a neural network. Source: https://www.ibm.com/topics/neural-networks
Directions
Feedforward - Data moves from input to output layer until a decision is reached or output is produced. (Note that the preceding neuron and layers diagrams are feedforward.)
Backpropagation - Data moves from output to input layer to calculate the error attributed to each neuron and adjust parameters for more accurate output.
.png?width=487&height=336&name=Untitled%20design%20(4).png)
A backpropagation neural network diagram. Source: https://ebrary.net/190741/engineering/propagation
Recurrent neural networks (RNNs) play a significant role in traditional AI techniques alongside other models like convolutional neural networks (CNNs) and reinforcement learning. They are particularly useful for processing sequences of data and are a key component in the broader landscape of machine learning methodologies.
Initially, all of a neural network’s weights and thresholds are set to random values. As training data is successively fed through, the weights and thresholds are continuously adjusted automatically until the neural network produces expected outputs based on provided inputs. This process requires trial and error over time, similar to the human learning process.
Let’s say we want to train a neural network to recognize handwritten numerical digits (0-9):
The neural network is initially untrained and cannot recognize any digits.
A training dataset of labeled images of handwritten digits is provided.
During training, the neural network takes an input image and predicts the digit represented. Perhaps the input image is labeled as a digit 1 but the neural network predicted a digit 7.
The prediction is compared to the correct digit label, calculating the difference as the error measurement.
The neural network adjusts its internal parameters, namely the weights and biases of its neurons, to minimize the error.
The learning process is repeated for all images in the training dataset.
After training, the neural network is evaluated using a separate test dataset to assess the accuracy of its predictions.
If the neural network performs well on the test dataset, it has successfully learned to identify handwritten digits.
Instead of the traditional programming approach of specifying steps to find the output, the computer is given the input and expected output and allowed to figure out the details on how to get from point A to point B. The what is specified and the how is delegated.
The main differentiator in learning modes is the use of labeled datasets for training. Labeled datasets allow for high-accuracy training, but are intensive in time and labor because the labeling tasks are manually performed by humans.
Supervised - Uses labeled inputs and outputs, allowing the machine learning models to measure their accuracy and improve over time.
Suitable for classification and regression problems: Classification is assigning input data into specific categories and regression is understanding the relationship between dependent and independent variables.
Unsupervised - Doesn't use labeled inputs and outputs; the machine learning models discover hidden patterns via clustering, association, and dimensionality reduction.
Clustering organizes unlabeled input data based on similarities or differences.
Association uses different rules to find relationships between variables in a specific input dataset.
Dimensionality reduction decreases the number of features (or dimensions) in an input dataset to a manageable size while preserving its data integrity.
Semi-Supervised - A hybrid approach that uses both labeled and unlabeled datasets.
Machine learning models use supervised learning for the labeled dataset to update model weights and unsupervised learning for the unlabeled dataset to minimize the difference in predicted outcomes.
Self-Supervised - Converts an unsupervised learning problem to a supervised learning problem.
The model trains itself by using one part of its dataset to predict the other parts and label them accurately.
Introduced in 2013, VAEs involve two neural networks: encoder and decoder. VAEs also have a third component in the middle known as the latent space.
The encoder converts input training data points into compressed representations, preserving critical information while discarding anything unnecessary. The compression process reduces the dimensionality of the dataset, allowing VAEs to deal with smaller and less complex data points while preserving relevancy.
The latent space holds all the compressed representations, also called latent representations. A latent representation is composed of latent attributes, each expressed as a probability distribution. The latent space acts as a bottleneck to distill the information from the encoder to the decoder while establishing useful correlations between the multitude of inputs. Creating latent representations prevents the VAEs from memorizing the training dataset and overfitting on it. Overfitting occurs when a model fits exactly or too closely to its training dataset, hindering it from generalizing or predicting with new unseen inputs.
The decoder reconstructs the original input data points from the compressed representations during training.
Novel content can be created by running new samplings of the latent representations through the decoder. The generation process of VAE models is typically faster than other model types but results in lower-quality output. VAEs have been typically applied in the use cases of synthetic data generation (for example, time series data such as music) and image reconstruction.
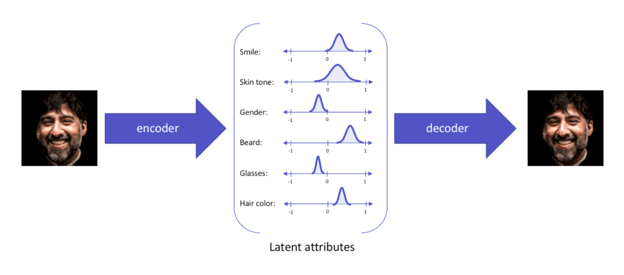
A VAE model diagram with latent space and attributes. Source: https://www.v7labs.com/blog/autoencoders-guide
Introduced in 2014, GANs pit two neural networks against each other: generator and discriminator. The generator creates new samples and the discriminator learns to distinguish whether the new samples are real or fake from existing data points. The generator and discriminator work together to continuously improve the new samples created until the discriminator can't tell the difference between real existing data and fake new data.
Novel content can be created by the generator. The generation process of GANs is generally fast with high-quality output compared with other model types. The downside is weak sample diversity, meaning these models work better for specific domains rather than generalized use cases. Due to their capability for fast, high-quality output, GANs have been widely used in generating multimedia, including voices and images.
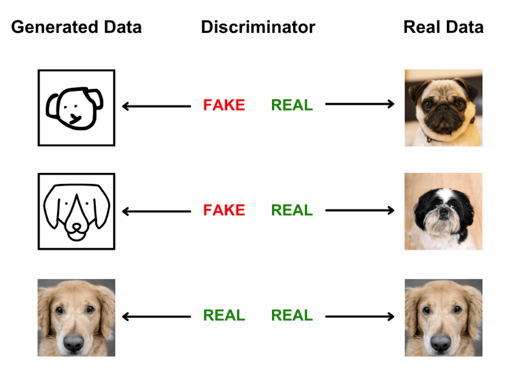
A simple illustration of how the generator and discriminator of a GAN model work together. Source: Author, inspired by https://developers.google.com/machine-learning/gan/gan_structure
Introduced in 2015, DDPMs involve a two-step training process: forward diffusion and reverse diffusion. The first step is forward diffusion which slowly adds random noise to the input training data points. The second step is reverse diffusion which slowly removes the noise from the output training data points to reconstruct the input samples.
Novel content can be created by running the reverse diffusion process with completely random noise. The training and generation process for DDPMs is time-consuming, but this model type generally creates the highest-quality output with strong sample diversity, being flexible for most use cases. Due to the detailed output, one common use case for diffusion models is generating superior images.

An illustration of forward and reverse diffusion in a DDPM model. Source: https://www.nvidia.com/en-us/glossary/data-science/generative-ai/
Introduced in 2017, the transformer machine learning architecture makes it possible to train models with a huge amount of training data without labeling them in advance. The reason is that transformers can process sequential input data in a non-sequential manner. Transformers combined the encoder-decoder setup with the concept of “attention.”
Encoder-decoder - The encoder converts unlabeled inputs into representations called “embeddings.” The decoder uses these embeddings and previous outputs to predict the next outputs.
Attention - A weight is assigned to each part of an input to signify its importance in context with the rest of the input.
Positional Encoding - A representation of the order in which input parts occur.
![]()

The word it is correctly referenced to the animal, which has the most attention. Source: https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
![]()

The word it is correctly referenced to the street, which has the most attention. Source: https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
Transformers can be “pre-trained” for generalized use cases with a massive amount of unlabeled training data. Later, a transformer can be specialized by fine-tuning it with a small amount of domain- or task-specific labeled training data. Such versatility makes transformers useful foundation models.
Large Language Models (LLMs) are language-based transformers with billions or even trillions of parameters allowing for advanced natural language processing. Parameters, in machine learning, are the variables present in the model during training, resembling a “model's knowledge bank.”
There are three classes of LLMs:
Encoder-only - Commonly used for non-generative tasks that can understand language, such as classification and extraction.
Decoder-only - Suitable for generative tasks, like creating new written content.
Encoder-decoder - Capable of both understanding and generating content, suitable for tasks such as translation and summarization.
The GPT-n generative AI models have been created by OpenAI. At the time of writing (July 2023), the latest released version is GPT-4, a multimodal decoder-only LLM that is capable of accepting image and text inputs and generating text outputs. It can perform advanced reasoning tasks, including code and math generation. Its predecessor, GPT-3, was pre-trained with 175 billion parameters.
ChatGPT is a chat application based on these GPT models with a focus on creating conversational responses. DALL-E is a text-to-image generative AI model based on a subset of GPT-3 and combined initially with a GAN model and later with a diffusion model.
Google's BERT (Bidirectional Encoder Representations from Transformers) is an encoder-only LLM used for search engines and customer-service chatbots.
Google's PaLM (Pathways Language Model) is a decoder-only LLM capable of advanced reasoning tasks, including code and math generation.
Google's T5 (Text-to-Text Transfer Transformer) is an encoder-decoder LLM used for both non-generative and generative tasks such as text summarization, question answering, translation, and sentiment analysis.
Despite the advancements made by generative AI models, there are still limitations and challenges. Generative AI systems, such as ChatGPT and Midjourney, rely on large datasets, including copyrighted materials, which prompt debates over fair use and copyright infringement. These systems face challenges related to accuracy, originality, and biases inherent in their outputs.
Scale - Due to the large scale of the computational infrastructure and massive size of datasets, the generative AI models require a large amount of computational and human resources to create and maintain.
OpenAI’s GPT-3 was pre-trained with 175 billion parameters. The size for GPT-4 is undisclosed publicly but estimated to be 1.7 trillion parameters. The “bigger is better” paradigm has the side effect of concentrating control over AI technologies in a handful of mega-companies that have sufficient computational and human resources. To counteract this trend, some data scientists and linguists are exploring functional language models that can be trained with smaller-sized datasets without diminishing performance.
Biases - Training datasets may contain gender, racial, social, and other biases that result in distorted outcomes.
The datasets selected to train the generative AI models are chosen by the people working on them. Dr. Gebru, a black female scientist previously on Google’s Ethical AI team, observed that the majority of people working on AI systems have been white males. An example of racial bias is misidentifying darker-toned faces as non-human. An illustration of gender bias is skewing certain occupations towards males or females. Some academics are looking for approaches to measuring, reducing, and avoiding biases present in training datasets. One debiasing approach can be to modify the underlying data distribution. For instance, with gender swapping, the pronouns and gendered words are substituted with the equivalents of the opposite gender.
Hallucinations - Generated contents that seem authoritative, but actually are untrue and completely made up.
When using a generative AI model for text generation, it may produce sentences or paragraphs that are grammatically correct but lack coherence or factual accuracy. One infamous occurrence was when Google’s Bard chatbot responded with false information to a prompt about the James Webb Space Telescope. The underlying causes are hard to isolate and diagnose but may be due to incomplete or inaccurate training data, issues with generation methodology, and unclear input context. Researchers are seeking to mitigate hallucinations by improving data quality and training, adding model constraints like output length, and incorporating human feedback.
The generative AI models and capabilities we know today wouldn't have been possible without previous advancements in the underlying machine learning technologies and deep learning models – namely, neural networks, unsupervised and semi-supervised learning modes, and VAEs, GANs, and DDPMs. The introduction of the transformer architecture paved the way for the development of modern LLMs that provide the groundwork for generative AI models. While we can use generative AI services and applications without understanding their underlying technologies and models, having this technical knowledge helps us anticipate new advances and choose the best tool for our specific needs.
Diana Cheung (ex-LinkedIn software engineer, USC MBA, and Codesmith alum) is a technical writer on technology and business. She is an avid learner and has a soft spot for tea and meows.